
复习材料,不建议阅读
语法分析
确定的自顶向下分析思想
确定的自顶向下分析方法,是从文法的开始符号出发,考虑如何根据当前的输入符号(单词符号)唯一地确定选用哪个产生式替换相应非终结符以往下推导,或如何构造一棵相应的语法树。
- 正规情况
文法右部始终由终结符号开始;相同左部时,右部是不同终结符号开始。
就可以直接根据当前输入符号决定产生式。
- 一般情况
右部不全由终结符开始;相同左部时,右部是不同符号开始;没有空产生式。
问题 A:当输入符号是 时,从 出发选择 还是 能推出 开头串?
- 舍空产生式
有空产生式了。
问题B:如果有一个输入串 ,推导过程:;在 的时候, 的产生式右部开始符号集都不包含 只有 产生式,就可以认为 的匹配实际依赖于 后面的符号 。
FIRST 集
FIRST(a) 是符号串 可以推导出的所有串的首终结符号集合,称为 的开始符号集或首符号集。
能推导出空的时候,。
由此解决问题 A,求 与 的 集(且它们恰好不相交)就可以得出输入符号选择哪个产生式。
FOLLOW 集
是在所有句型中紧跟在非终结符 后面的终结符号集合。# 是输入串的结束符,也称输入串括号。
能推导出 的时候,。
结合 由此解决问题 B, 不能同时推导出空,替换仍是唯一确定的。
SELECT 集
是产生式 的选择符号集,表示当遇到这些输入符号时应该选择该产生式进行推导。
- 若 ,则 。
- 若 ,则 。
简单来说就是, 不含空选 ,含空就 去掉空并 。
文法
概念
一个上下文无关文法是 文法的充分必要条件是,对每个非终结符 的两个不同产生式 和 ,满足:。
其中 和 不同时能推导出 。
判别
- 求能推出 ε 的非终结符
建立标志位数组(“未定”/“是”/“否”),扫描产生式:
- 右部含终结符 → 标记"否"
- 右部为 ε → 标记"是"
- 重复扫描直到标志不再变化
- 计算 FIRST 集
对每个符号 X:
- 若 ,则
- 若 且 ,则
- 若 且 ,则
- 若 且 ,则将 (除 )加入
- 计算 FOLLOW 集
对每个非终结符 A:
- 开始符号 S:
- 产生式 :(非空)加入
- 若 : 加入
- 计算 SELECT 集并判别
对每个产生式 :
- 若 ,则
- 若 ,则
LL(1) 条件:对每个非终结符 A 的不同产生式,SELECT 集的交集为空集。
不确定的自顶向下分析思想
当文法不满足 LL(1) 时,不能用确定的自顶向下分析,但可用不确定的自顶向下分析(带回溯的自顶向下分析)。
引起回溯的原因是:在文法中当关于某个非终结符的产生式有多个候选时,而面临当前的输入符无法确定选用唯一的产生式,从而引起回溯。
回溯分析
- 由于相同左部的产生式的右部 FIRST 集交集不为空而引起回溯
输入串 xay,先选 A → ab,xa 匹配后当前符 y 与 b 不匹配,回溯改选 A → a,匹配成功。
- 由于相同左部非终结符的右部存在 ε 的产生式,且该非终结符的 FOLLOW 集中含有其他产生式右部 FIRST 集的元素
输入串 ab#,先选 S → aA,a 匹配后 A 选 A → cA,但 c 与 b 不匹配,回溯改选 A → ε,b 与 S 的 FOLLOW 集中的 b 匹配,匹配成功。
- 由于文法含有左递归而引起回溯
输入串 baa#,先选 S → b,输入串未分析完,回溯改选 S → Sa,再选 S → b,得到 ba,但输入串还有 a#,继续回溯,最终得到 baa,匹配成功。
带回溯分析代价很高,效率很低,在实用编译程序中几乎不用。
某些非 LL(1)文法到 LL(1)文法的等价变换
左递归消除
文法中含有左递归时不能采用确定的自顶向下分析法。左递归分为直接左递归和间接左递归。
直接左递归消除
形如 的产生式称为直接左递归。
例:文法 含有直接左递归:
该文法产生的语言 。输入串 baaa# 应是该语言的句子,但用自顶向下分析时,当输入符为 b 时,为与 S 匹配则应选用 推导,但这样就推不出后边部分;而若用 推导则无法确定到什么时候才用 替换。
消除方法:把直接左递归改写为右递归。对文法 可改写为:
改写后的文法和原文法产生的语言句子集都为 ,且改写后的文法为 LL(1) 文法。
一般情况下,假定关于 的全部产生式是:
其中 ()不以 开头,消除直接左递归后改写为:
间接左递归消除
形如 , 等可以形成推导 的产生式称为间接左递归。
例:文法 含有间接左递归:
若有输入串为 adbcbcbc#,当分析过程至 时, 若用产生式 替换,则分析过程终止,不能推出 adbcbcbc#;而若选用产生式 ,则会出现无法确定何时终止的情况。
消除方法:先通过产生式非终结符置换,将间接左递归变为直接左递归,然后再按消除直接左递归的方法处理。
以文法 为例,用产生式 和 的右部置换产生式 中的非终结符 ,得到左部为 的产生式:
消除左递归后得:
再把原来其余的产生式 和 加入,最终文法为:
该文法与 等价,即它们产生相同的句子集。
消除一切左递归的算法
对文法中一切左递归的消除要求文法中不含回路,即无 的推导。满足这个要求的充分条件是,文法中不包含形如 的有害规则和 的空产生式。
算法步骤如下:
- 把文法的所有非终结符按某一顺序排序,例如:
- FOR i = 1 TO n DO
- FOR j = 1 TO i-1 DO
- 若 的所有产生式为
- 将其替换形如 的产生式得到
- 消除 中的一切直接左递归
- FOR j = 1 TO i-1 DO
- 去掉无用产生式
例:按上述方法消除如下文法的一切左递归:
若非终结符排序为 :
- 左部为 的产生式 无直接左递归
- 左部为 的产生式 中右部不含
- 把产生式 的右部代入产生式 得:
- 再将产生式 的右部代入得:
- 对产生式消除直接左递归得:
最终文法变为:
若非终结符的排序为 ,则把产生式 代入产生式 得:,再将此代入产生式 得:。消除该产生式的左递归后,文法变为:
由于 为不可到达的非终结符,所以以 为左部及包含 的产生式应删除。
当非终结符的排序不同时,最后结果的产生式形式不同,但它们是等价的。
提取左公因子
若文法中含有形如 的产生式,会导致相同左部产生式的 FIRST 集相交,不满足 LL(1) 条件。
可将产生式等价变换为:
写成一般形式:(其中 不以 开头)
提取左公共因子后变为:
若 中仍含有左公共因子,可再次提取,直到无左公共因子为止。
例 1:文法 的产生式为
对产生式(1)、(2)提取左公共因子后得:
进一步变换为:
例 2:文法 的产生式为
产生式(2)的右部以非终结符 开始,左公共因子可能是隐式的。用产生式(3)、(4)的右部替换产生式(2)中的 ,可得:
提取产生式(1)、(2)的左公共因子得:
引进新非终结符 后得 为:
注意事项:
-
提取左公共因子后,可能使某些产生式变成无用产生式,需要对文法重新压缩。
-
某些文法不能在有限步骤内提取完左公共因子。例如文法 :
用产生式(2)、(3)的右部替换产生式(1)中的 、,再提取左公共因子,只能使文法的产生式越来越多,无限增加下去,而不能得到提取左公共因子的预期结果。
- 一个文法提取了左公共因子后,只解决了相同左部产生式右部的 FIRST 集不相交的问题。当改写后的文法不含空产生式,且无左递归时,则改写后的文法是 LL(1) 文法;若还有空产生式时,则还需用 LL(1) 文法的判别方式进行判断才能确定是否为 LL(1) 文法。
LL(1) 分析的实现
递归下降分析
核心思想:为每个非终结符编写一个递归函数,函数内根据当前输入符号查 SELECT 集选择产生式,递归调用对应函数。
构造方法:
- 为每个非终结符 编写函数
A() - 函数体结构:
- 根据当前输入符号
lookahead选择产生式 - 对产生式右部的每个符号:
- 终结符:匹配并读入下一符号
- 非终结符:调用对应函数
- 根据当前输入符号
示例:文法 ,,
消除左递归后:,,,,
1 | def E(): |
优点:代码结构清晰,易于理解和调试,可手工编写。
缺点:每个文法需单独编程,修改文法需重写代码。
表驱动分析
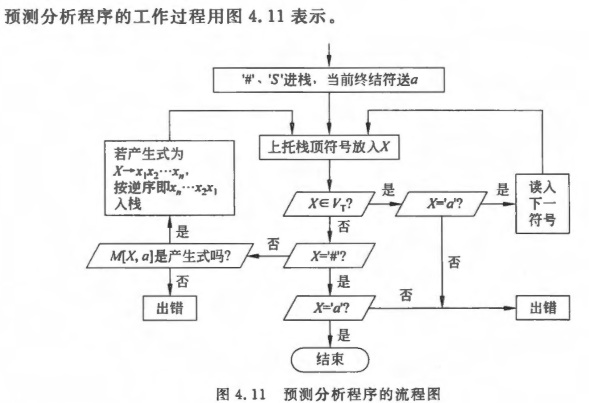
核心思想:用一张预测分析表 存储"非终结符 遇到输入符号 时选择哪个产生式",用栈模拟推导过程。
分析表构造:对每个产生式 ,对 中的每个终结符 ,令 。
分析过程:
1 | 栈初始化: [#, S] (# 是栈底, S 是开始符号) |
示例:文法 ,,,,
分析表(部分):
| 非终结符 | id | + | * | ( | ) | # |
|---|---|---|---|---|---|---|
| E | ||||||
| E’ | ||||||
| T | ||||||
| T’ | ||||||
| F |
分析 id+id 的过程:
1 | 栈 输入 动作 |
伪代码实现:
1 | def LL1_parse(input_string, parse_table): |
优点:通用性强,修改文法只需重新生成分析表,适合自动化工具生成。
缺点:需要预先构造分析表,不如递归下降直观。
LL(1) 分析中的错误处理
错误处理包含两个任务:报错(指出错误位置和类型)和错误恢复(使分析继续进行)。
错误发生的情况
LL(1) 分析中有两种错误情况:
- 栈顶终结符与当前输入不匹配
- 栈顶非终结符 面临输入符号 ,但 为空
应急恢复 (Panic Mode)
核心思想:跳过输入符号直到遇到"同步符号",使分析能继续。
同步符号选择:将 或 中的符号作为非终结符 的同步符号。
恢复策略:
- 遇到 中的符号:弹出栈顶的 ,继续分析
- 遇到 中的符号:保留 在栈顶,根据 恢复分析
示例:若 在栈顶,当前输入是 ),但 为空:
1 | FOLLOW(E) = {), #} |
短语层恢复 (Phrase-Level)
核心思想:根据当前语法单位的上下文进行更精确的恢复。
流程:
-
进入语法单位时:
- 检查当前符号是否属于 (通常取 集)
- 若不属于,报错并跳过 之外的符号
- 遇到 中符号:重新分析该单位
- 遇到 中符号:退出该单位
-
离开语法单位时:
- 检查当前符号是否属于 (基于 集)
- 若不属于,报错并跳过 之外的符号
递归下降中的实现示例:
文法:,
1 | def ParseB(EndSym): |
关键点:不同上下文传入不同的 参数,体现"短语层"的含义。例如方括号内调用 ParseA 时传入 EndSym ∪ {]},圆括号内传入 EndSym ∪ {)}。
两种方法对比
| 方法 | 优点 | 缺点 |
|---|---|---|
| 应急恢复 | 实现简单,通用 | 恢复不够精确,可能跳过过多符号 |
| 短语层恢复 | 考虑上下文,恢复更精确 | 实现复杂,需为每个语法单位设计 |
实际编译器(如 PL/0)通常采用短语层恢复,在进入和退出语法单位时调用检查函数,根据 和 集合进行错误检测和恢复。